Przetestuj SWOJؤ„ Firmؤ™ w Minuty
Utwأ³rz konto i uruchom swojego chatbota AI w kilka minut. W peإ‚ni konfigurowalny, bez koniecznoإ›ci kodowania - zacznij angaإ¼owaؤ‡ swoich klientأ³w natychmiast!
Gotowy w kilka minut
Nie wymaga programowania
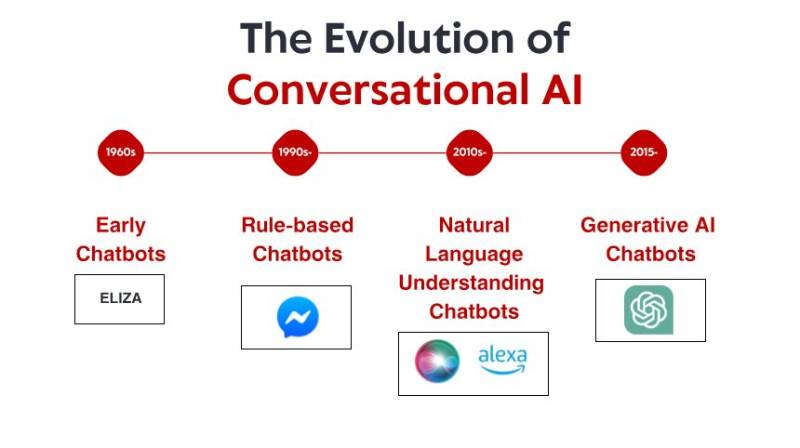
Skromne poczؤ…tki: wczesne systemy oparte na reguإ‚ach
Historia konwersacyjnej sztucznej inteligencji zaczyna siؤ™ w latach 60., na dإ‚ugo zanim smartfony i asystenci gإ‚osowi stali siؤ™ podstawowymi urzؤ…dzeniami gospodarstwa domowego. W maإ‚ym laboratorium w MIT informatyk Joseph Weizenbaum stworzyإ‚ to, co wielu uwaإ¼a za pierwszego chatbota: ELIZA. Zaprojektowana, aby symulowaؤ‡ psychoterapeutؤ™ Rogersa, ELIZA dziaإ‚aإ‚a poprzez proste reguإ‚y dopasowywania wzorcأ³w i podstawiania. Gdy uإ¼ytkownik wpisywaإ‚ â€Jestem smutnyâ€, ELIZA mogإ‚a odpowiedzieؤ‡ â€Dlaczego jesteإ› smutny?†– tworzؤ…c iluzjؤ™ zrozumienia poprzez przeformuإ‚owanie stwierdzeإ„ w pytania.
To, co czyniإ‚o ELIZؤک niezwykإ‚ؤ…, to nie jej wyrafinowanie techniczne – wedإ‚ug dzisiejszych standardأ³w program byإ‚ niesamowicie prosty. Raczej gإ‚ؤ™boki wpإ‚yw, jaki wywarإ‚ na uإ¼ytkownikأ³w. Pomimo إ›wiadomoإ›ci, إ¼e rozmawiajؤ… z programem komputerowym bez rzeczywistego zrozumienia, wiele osأ³b nawiؤ…zaإ‚o emocjonalne wiؤ™zi z ELIZؤ„, dzielؤ…c siؤ™ gإ‚ؤ™boko osobistymi myإ›lami i uczuciami. To zjawisko, ktأ³re sam Weizenbaum uwaإ¼aإ‚ za niepokojؤ…ce, ujawniإ‚o coإ› fundamentalnego na temat psychologii czإ‚owieka i naszej gotowoإ›ci do antropomorfizacji nawet najprostszych interfejsأ³w konwersacyjnych.
Przez lata 70. i 80. oparte na reguإ‚ach chatboty podؤ…إ¼aإ‚y za szablonem ELIZY, wprowadzajؤ…c stopniowe ulepszenia. Programy takie jak PARRY (symulujؤ…cy schizofrenika paranoidalnego) i RACTER (ktأ³ry â€byإ‚ autorem†ksiؤ…إ¼ki zatytuإ‚owanej â€The Policeman's Beard is Half Constructedâ€) pozostaإ‚y mocno w paradygmacie opartym na reguإ‚ach – wykorzystujؤ…c wstؤ™pnie zdefiniowane wzorce, dopasowywanie sإ‚أ³w kluczowych i szablonowe odpowiedzi.
Te wczesne systemy miaإ‚y powaإ¼ne ograniczenia. Nie mogإ‚y w rzeczywistoإ›ci rozumieؤ‡ jؤ™zyka, uczyؤ‡ siؤ™ z interakcji ani dostosowywaؤ‡ siؤ™ do nieoczekiwanych danych wejإ›ciowych. Ich wiedza ograniczaإ‚a siؤ™ do reguإ‚ wyraإ؛nie zdefiniowanych przez ich programistأ³w. Kiedy uإ¼ytkownicy nieuchronnie wykraczali poza te granice, iluzja inteligencji szybko siؤ™ rozpadaإ‚a, ujawniajؤ…c mechanicznؤ… naturؤ™ pod spodem. Pomimo tych ograniczeإ„ te pionierskie systemy ustanowiإ‚y fundament, na ktأ³rym zbuduje siؤ™ caإ‚a przyszإ‚a konwersacyjna sztuczna inteligencja.
To, co czyniإ‚o ELIZؤک niezwykإ‚ؤ…, to nie jej wyrafinowanie techniczne – wedإ‚ug dzisiejszych standardأ³w program byإ‚ niesamowicie prosty. Raczej gإ‚ؤ™boki wpإ‚yw, jaki wywarإ‚ na uإ¼ytkownikأ³w. Pomimo إ›wiadomoإ›ci, إ¼e rozmawiajؤ… z programem komputerowym bez rzeczywistego zrozumienia, wiele osأ³b nawiؤ…zaإ‚o emocjonalne wiؤ™zi z ELIZؤ„, dzielؤ…c siؤ™ gإ‚ؤ™boko osobistymi myإ›lami i uczuciami. To zjawisko, ktأ³re sam Weizenbaum uwaإ¼aإ‚ za niepokojؤ…ce, ujawniإ‚o coإ› fundamentalnego na temat psychologii czإ‚owieka i naszej gotowoإ›ci do antropomorfizacji nawet najprostszych interfejsأ³w konwersacyjnych.
Przez lata 70. i 80. oparte na reguإ‚ach chatboty podؤ…إ¼aإ‚y za szablonem ELIZY, wprowadzajؤ…c stopniowe ulepszenia. Programy takie jak PARRY (symulujؤ…cy schizofrenika paranoidalnego) i RACTER (ktأ³ry â€byإ‚ autorem†ksiؤ…إ¼ki zatytuإ‚owanej â€The Policeman's Beard is Half Constructedâ€) pozostaإ‚y mocno w paradygmacie opartym na reguإ‚ach – wykorzystujؤ…c wstؤ™pnie zdefiniowane wzorce, dopasowywanie sإ‚أ³w kluczowych i szablonowe odpowiedzi.
Te wczesne systemy miaإ‚y powaإ¼ne ograniczenia. Nie mogإ‚y w rzeczywistoإ›ci rozumieؤ‡ jؤ™zyka, uczyؤ‡ siؤ™ z interakcji ani dostosowywaؤ‡ siؤ™ do nieoczekiwanych danych wejإ›ciowych. Ich wiedza ograniczaإ‚a siؤ™ do reguإ‚ wyraإ؛nie zdefiniowanych przez ich programistأ³w. Kiedy uإ¼ytkownicy nieuchronnie wykraczali poza te granice, iluzja inteligencji szybko siؤ™ rozpadaإ‚a, ujawniajؤ…c mechanicznؤ… naturؤ™ pod spodem. Pomimo tych ograniczeإ„ te pionierskie systemy ustanowiإ‚y fundament, na ktأ³rym zbuduje siؤ™ caإ‚a przyszإ‚a konwersacyjna sztuczna inteligencja.
Rewolucja wiedzy: systemy eksperckie i ustrukturyzowane informacje
Lata 80. i poczؤ…tek lat 90. to czas rozwoju systemأ³w eksperckich – programأ³w AI zaprojektowanych do rozwiؤ…zywania zإ‚oإ¼onych problemأ³w poprzez naإ›ladowanie zdolnoإ›ci podejmowania decyzji przez ekspertأ³w w okreإ›lonych dziedzinach. Choؤ‡ nie zostaإ‚y zaprojektowane przede wszystkim do konwersacji, systemy te stanowiإ‚y waإ¼ny krok ewolucyjny dla konwersacyjnej AI, wprowadzajؤ…c bardziej wyrafinowanؤ… reprezentacjؤ™ wiedzy.
Systemy eksperckie, takie jak MYCIN (ktأ³ry diagnozowaإ‚ infekcje bakteryjne) i DENDRAL (ktأ³ry identyfikowaإ‚ zwiؤ…zki chemiczne), organizowaإ‚y informacje w ustrukturyzowanych bazach wiedzy i wykorzystywaإ‚y silniki wnioskowania do wyciؤ…gania wnioskأ³w. W przypadku zastosowania w interfejsach konwersacyjnych podejإ›cie to pozwoliإ‚o chatbotom wyjإ›ؤ‡ poza proste dopasowywanie wzorcأ³w w kierunku czegoإ› przypominajؤ…cego rozumowanie – przynajmniej w wؤ…skich dziedzinach.
Firmy zaczؤ™إ‚y wdraإ¼aؤ‡ praktyczne aplikacje, takie jak zautomatyzowane systemy obsإ‚ugi klienta, wykorzystujؤ…c tؤ™ technologiؤ™. Systemy te zazwyczaj wykorzystywaإ‚y drzewa decyzyjne i interakcje oparte na menu, a nie konwersacje swobodne, ale stanowiإ‚y wczesne prأ³by automatyzacji interakcji, ktأ³re wczeإ›niej wymagaإ‚y interwencji czإ‚owieka.
Ograniczenia pozostaإ‚y znaczؤ…ce. Systemy te byإ‚y kruche i nie byإ‚y w stanie sprawnie obsإ‚ugiwaؤ‡ nieoczekiwanych danych wejإ›ciowych. Wymagaإ‚y ogromnego wysiإ‚ku ze strony inإ¼ynierأ³w wiedzy, aby rؤ™cznie kodowaؤ‡ informacje i reguإ‚y. I co moإ¼e najwaإ¼niejsze, nadal nie potrafili w peإ‚ni zrozumieؤ‡ jؤ™zyka naturalnego w jego peإ‚nej zإ‚oإ¼onoإ›ci i niejednoznacznoإ›ci.
Niemniej jednak ta epoka ustanowiإ‚a waإ¼ne koncepcje, ktأ³re pأ³إ؛niej miaإ‚y staؤ‡ siؤ™ kluczowe dla wspأ³إ‚czesnej konwersacyjnej sztucznej inteligencji: ustrukturyzowanؤ… reprezentacjؤ™ wiedzy, logiczne wnioskowanie i specjalizacjؤ™ domenowؤ…. Scena byإ‚a przygotowywana do zmiany paradygmatu, chociaإ¼ technologia jeszcze nie byإ‚a gotowa.
Systemy eksperckie, takie jak MYCIN (ktأ³ry diagnozowaإ‚ infekcje bakteryjne) i DENDRAL (ktأ³ry identyfikowaإ‚ zwiؤ…zki chemiczne), organizowaإ‚y informacje w ustrukturyzowanych bazach wiedzy i wykorzystywaإ‚y silniki wnioskowania do wyciؤ…gania wnioskأ³w. W przypadku zastosowania w interfejsach konwersacyjnych podejإ›cie to pozwoliإ‚o chatbotom wyjإ›ؤ‡ poza proste dopasowywanie wzorcأ³w w kierunku czegoإ› przypominajؤ…cego rozumowanie – przynajmniej w wؤ…skich dziedzinach.
Firmy zaczؤ™إ‚y wdraإ¼aؤ‡ praktyczne aplikacje, takie jak zautomatyzowane systemy obsإ‚ugi klienta, wykorzystujؤ…c tؤ™ technologiؤ™. Systemy te zazwyczaj wykorzystywaإ‚y drzewa decyzyjne i interakcje oparte na menu, a nie konwersacje swobodne, ale stanowiإ‚y wczesne prأ³by automatyzacji interakcji, ktأ³re wczeإ›niej wymagaإ‚y interwencji czإ‚owieka.
Ograniczenia pozostaإ‚y znaczؤ…ce. Systemy te byإ‚y kruche i nie byإ‚y w stanie sprawnie obsإ‚ugiwaؤ‡ nieoczekiwanych danych wejإ›ciowych. Wymagaإ‚y ogromnego wysiإ‚ku ze strony inإ¼ynierأ³w wiedzy, aby rؤ™cznie kodowaؤ‡ informacje i reguإ‚y. I co moإ¼e najwaإ¼niejsze, nadal nie potrafili w peإ‚ni zrozumieؤ‡ jؤ™zyka naturalnego w jego peإ‚nej zإ‚oإ¼onoإ›ci i niejednoznacznoإ›ci.
Niemniej jednak ta epoka ustanowiإ‚a waإ¼ne koncepcje, ktأ³re pأ³إ؛niej miaإ‚y staؤ‡ siؤ™ kluczowe dla wspأ³إ‚czesnej konwersacyjnej sztucznej inteligencji: ustrukturyzowanؤ… reprezentacjؤ™ wiedzy, logiczne wnioskowanie i specjalizacjؤ™ domenowؤ…. Scena byإ‚a przygotowywana do zmiany paradygmatu, chociaإ¼ technologia jeszcze nie byإ‚a gotowa.
Rozumienie jؤ™zyka naturalnego: przeإ‚om w lingwistyce obliczeniowej
Pod koniec lat 90. i na poczؤ…tku XXI wieku zaczؤ™to zwracaؤ‡ coraz wiؤ™kszؤ… uwagؤ™ na przetwarzanie jؤ™zyka naturalnego (NLP) i lingwistykؤ™ obliczeniowؤ…. Zamiast prأ³bowaؤ‡ rؤ™cznie kodowaؤ‡ reguإ‚y dla kaإ¼dej moإ¼liwej interakcji, naukowcy zaczؤ™li opracowywaؤ‡ metody statystyczne, aby pomأ³c komputerom zrozumieؤ‡ inherentne wzorce jؤ™zyka ludzkiego.
Ta zmiana byإ‚a moإ¼liwa dziؤ™ki kilku czynnikom: rosnؤ…cej mocy obliczeniowej, lepszym algorytmom i, co najwaإ¼niejsze, dostؤ™pnoإ›ci duإ¼ych korpusأ³w tekstowych, ktأ³re moإ¼na byإ‚o analizowaؤ‡ w celu identyfikacji wzorcأ³w jؤ™zykowych. Systemy zaczؤ™إ‚y wإ‚ؤ…czaؤ‡ techniki takie jak:
Tagging czؤ™إ›ci mowy: Identyfikowanie, czy sإ‚owa funkcjonujؤ… jako rzeczowniki, czasowniki, przymiotniki itp.
Rozpoznawanie nazwanych bytأ³w: Wykrywanie i klasyfikowanie nazw wإ‚asnych (ludzie, organizacje, lokalizacje).
Analiza sentymentأ³w: Okreإ›lanie emocjonalnego tonu tekstu.
Analiza skإ‚adniowa: Analiza struktury zdania w celu identyfikacji relacji gramatycznych miؤ™dzy sإ‚owami.
Jednym z przeإ‚omowych rozwiؤ…zaإ„ byإ‚ Watson firmy IBM, ktأ³ry w 2011 roku pokonaإ‚ ludzkich mistrzأ³w w teleturnieju Jeopardy! Chociaإ¼ nie byإ‚ to إ›ciإ›le system konwersacyjny, Watson wykazaإ‚ siؤ™ bezprecedensowymi umiejؤ™tnoإ›ciami rozumienia pytaإ„ w jؤ™zyku naturalnym, przeszukiwania ogromnych repozytoriأ³w wiedzy i formuإ‚owania odpowiedzi — umiejؤ™tnoإ›ciami, ktأ³re miaإ‚y okazaؤ‡ siؤ™ niezbؤ™dne dla nastؤ™pnej generacji chatbotأ³w.
Wkrأ³tce pojawiإ‚y siؤ™ aplikacje komercyjne. W 2011 roku uruchomiono Siri firmy Apple, udostؤ™pniajؤ…c interfejsy konwersacyjne przeciؤ™tnym konsumentom. Choؤ‡ Siri jest ograniczona przez dzisiejsze standardy, stanowiإ‚a znaczؤ…cy postؤ™p w udostؤ™pnianiu asystentأ³w AI zwykإ‚ym uإ¼ytkownikom. Pأ³إ؛niej pojawiإ‚y siؤ™ Cortana firmy Microsoft, Asystent Google i Alexa firmy Amazon, z ktأ³rych kaإ¼dy wprowadzaإ‚ najnowoczeإ›niejsze rozwiؤ…zania w zakresie konwersacyjnej sztucznej inteligencji skierowanej do konsumentأ³w.
Pomimo tych postؤ™pأ³w systemy z tej ery nadal miaإ‚y problemy z kontekstem, rozumowaniem opartym na zdrowym rozsؤ…dku i generowaniem prawdziwie naturalnie brzmiؤ…cych odpowiedzi. Byإ‚y bardziej wyrafinowane niإ¼ ich przodkowie bazujؤ…cy na reguإ‚ach, ale pozostaإ‚y zasadniczo ograniczone w rozumieniu jؤ™zyka i إ›wiata.
Ta zmiana byإ‚a moإ¼liwa dziؤ™ki kilku czynnikom: rosnؤ…cej mocy obliczeniowej, lepszym algorytmom i, co najwaإ¼niejsze, dostؤ™pnoإ›ci duإ¼ych korpusأ³w tekstowych, ktأ³re moإ¼na byإ‚o analizowaؤ‡ w celu identyfikacji wzorcأ³w jؤ™zykowych. Systemy zaczؤ™إ‚y wإ‚ؤ…czaؤ‡ techniki takie jak:
Tagging czؤ™إ›ci mowy: Identyfikowanie, czy sإ‚owa funkcjonujؤ… jako rzeczowniki, czasowniki, przymiotniki itp.
Rozpoznawanie nazwanych bytأ³w: Wykrywanie i klasyfikowanie nazw wإ‚asnych (ludzie, organizacje, lokalizacje).
Analiza sentymentأ³w: Okreإ›lanie emocjonalnego tonu tekstu.
Analiza skإ‚adniowa: Analiza struktury zdania w celu identyfikacji relacji gramatycznych miؤ™dzy sإ‚owami.
Jednym z przeإ‚omowych rozwiؤ…zaإ„ byإ‚ Watson firmy IBM, ktأ³ry w 2011 roku pokonaإ‚ ludzkich mistrzأ³w w teleturnieju Jeopardy! Chociaإ¼ nie byإ‚ to إ›ciإ›le system konwersacyjny, Watson wykazaإ‚ siؤ™ bezprecedensowymi umiejؤ™tnoإ›ciami rozumienia pytaإ„ w jؤ™zyku naturalnym, przeszukiwania ogromnych repozytoriأ³w wiedzy i formuإ‚owania odpowiedzi — umiejؤ™tnoإ›ciami, ktأ³re miaإ‚y okazaؤ‡ siؤ™ niezbؤ™dne dla nastؤ™pnej generacji chatbotأ³w.
Wkrأ³tce pojawiإ‚y siؤ™ aplikacje komercyjne. W 2011 roku uruchomiono Siri firmy Apple, udostؤ™pniajؤ…c interfejsy konwersacyjne przeciؤ™tnym konsumentom. Choؤ‡ Siri jest ograniczona przez dzisiejsze standardy, stanowiإ‚a znaczؤ…cy postؤ™p w udostؤ™pnianiu asystentأ³w AI zwykإ‚ym uإ¼ytkownikom. Pأ³إ؛niej pojawiإ‚y siؤ™ Cortana firmy Microsoft, Asystent Google i Alexa firmy Amazon, z ktأ³rych kaإ¼dy wprowadzaإ‚ najnowoczeإ›niejsze rozwiؤ…zania w zakresie konwersacyjnej sztucznej inteligencji skierowanej do konsumentأ³w.
Pomimo tych postؤ™pأ³w systemy z tej ery nadal miaإ‚y problemy z kontekstem, rozumowaniem opartym na zdrowym rozsؤ…dku i generowaniem prawdziwie naturalnie brzmiؤ…cych odpowiedzi. Byإ‚y bardziej wyrafinowane niإ¼ ich przodkowie bazujؤ…cy na reguإ‚ach, ale pozostaإ‚y zasadniczo ograniczone w rozumieniu jؤ™zyka i إ›wiata.
Uczenie maszynowe i podejإ›cie oparte na danych
Poإ‚owa lat 2010. oznaczaإ‚a kolejnؤ… zmianؤ™ paradygmatu w konwersacyjnej sztucznej inteligencji wraz z powszechnym przyjؤ™ciem technik uczenia maszynowego. Zamiast polegaؤ‡ na rؤ™cznie tworzonych reguإ‚ach lub ograniczonych modelach statystycznych, inإ¼ynierowie zaczؤ™li budowaؤ‡ systemy, ktأ³re mogإ‚y uczyؤ‡ siؤ™ wzorcأ³w bezpoإ›rednio z danych — i to mnأ³stwa danych.
W tej epoce nastؤ…piإ‚ wzrost klasyfikacji intencji i ekstrakcji encji jako podstawowych komponentأ³w architektury konwersacyjnej. Gdy uإ¼ytkownik skإ‚adaإ‚ إ¼ؤ…danie, system:
Klasyfikowaإ‚ ogأ³lnؤ… intencjؤ™ (np. rezerwacjؤ™ lotu, sprawdzenie pogody, odtwarzanie muzyki)
Ekstrahowaإ‚ odpowiednie encje (np. lokalizacje, daty, tytuإ‚y piosenek)
Mapowaإ‚ je na okreإ›lone dziaإ‚ania lub odpowiedzi
Uruchomienie przez Facebooka (obecnie Meta) platformy Messenger w 2016 r. umoإ¼liwiإ‚o programistom tworzenie chatbotأ³w, ktأ³re mogإ‚y dotrzeؤ‡ do milionأ³w uإ¼ytkownikأ³w, wywoإ‚ujؤ…c falؤ™ zainteresowania komercyjnego. Wiele firm spieszyإ‚o siؤ™ z wdraإ¼aniem chatbotأ³w, chociaإ¼ wyniki byإ‚y rأ³إ¼ne. Wczesne komercyjne wdroإ¼enia czؤ™sto frustrowaإ‚y uإ¼ytkownikأ³w ograniczonym zrozumieniem i sztywnymi przepإ‚ywami konwersacji.
W tym okresie ewoluowaإ‚a rأ³wnieإ¼ architektura techniczna systemأ³w konwersacyjnych. Typowe podejإ›cie obejmowaإ‚o potok wyspecjalizowanych komponentأ³w:
Automatyczne rozpoznawanie mowy (dla interfejsأ³w gإ‚osowych)
Rozumienie jؤ™zyka naturalnego
Zarzؤ…dzanie dialogiem
Generowanie jؤ™zyka naturalnego
Tekst na mowؤ™ (dla interfejsأ³w gإ‚osowych)
Kaإ¼dy komponent moإ¼na byإ‚o zoptymalizowaؤ‡ osobno, co pozwalaإ‚o na stopniowe ulepszenia. Jednak te architektury potokowe czasami cierpiaإ‚y na propagacjؤ™ bإ‚ؤ™dأ³w – bإ‚ؤ™dy na wczesnych etapach kaskadowo przechodziإ‚y przez system.
Chociaإ¼ uczenie maszynowe znacznie poprawiإ‚o moإ¼liwoإ›ci, systemy nadal miaإ‚y problemy z utrzymaniem kontekstu podczas dإ‚ugich konwersacji, zrozumieniem ukrytych informacji i generowaniem naprawdؤ™ zrأ³إ¼nicowanych i naturalnych odpowiedzi. Kolejny przeإ‚om wymagaإ‚ bardziej radykalnego podejإ›cia.
W tej epoce nastؤ…piإ‚ wzrost klasyfikacji intencji i ekstrakcji encji jako podstawowych komponentأ³w architektury konwersacyjnej. Gdy uإ¼ytkownik skإ‚adaإ‚ إ¼ؤ…danie, system:
Klasyfikowaإ‚ ogأ³lnؤ… intencjؤ™ (np. rezerwacjؤ™ lotu, sprawdzenie pogody, odtwarzanie muzyki)
Ekstrahowaإ‚ odpowiednie encje (np. lokalizacje, daty, tytuإ‚y piosenek)
Mapowaإ‚ je na okreإ›lone dziaإ‚ania lub odpowiedzi
Uruchomienie przez Facebooka (obecnie Meta) platformy Messenger w 2016 r. umoإ¼liwiإ‚o programistom tworzenie chatbotأ³w, ktأ³re mogإ‚y dotrzeؤ‡ do milionأ³w uإ¼ytkownikأ³w, wywoإ‚ujؤ…c falؤ™ zainteresowania komercyjnego. Wiele firm spieszyإ‚o siؤ™ z wdraإ¼aniem chatbotأ³w, chociaإ¼ wyniki byإ‚y rأ³إ¼ne. Wczesne komercyjne wdroإ¼enia czؤ™sto frustrowaإ‚y uإ¼ytkownikأ³w ograniczonym zrozumieniem i sztywnymi przepإ‚ywami konwersacji.
W tym okresie ewoluowaإ‚a rأ³wnieإ¼ architektura techniczna systemأ³w konwersacyjnych. Typowe podejإ›cie obejmowaإ‚o potok wyspecjalizowanych komponentأ³w:
Automatyczne rozpoznawanie mowy (dla interfejsأ³w gإ‚osowych)
Rozumienie jؤ™zyka naturalnego
Zarzؤ…dzanie dialogiem
Generowanie jؤ™zyka naturalnego
Tekst na mowؤ™ (dla interfejsأ³w gإ‚osowych)
Kaإ¼dy komponent moإ¼na byإ‚o zoptymalizowaؤ‡ osobno, co pozwalaإ‚o na stopniowe ulepszenia. Jednak te architektury potokowe czasami cierpiaإ‚y na propagacjؤ™ bإ‚ؤ™dأ³w – bإ‚ؤ™dy na wczesnych etapach kaskadowo przechodziإ‚y przez system.
Chociaإ¼ uczenie maszynowe znacznie poprawiإ‚o moإ¼liwoإ›ci, systemy nadal miaإ‚y problemy z utrzymaniem kontekstu podczas dإ‚ugich konwersacji, zrozumieniem ukrytych informacji i generowaniem naprawdؤ™ zrأ³إ¼nicowanych i naturalnych odpowiedzi. Kolejny przeإ‚om wymagaإ‚ bardziej radykalnego podejإ›cia.
Rewolucja Transformerأ³w: Modele Jؤ™zyka Neuronalnego
Rok 2017 byإ‚ przeإ‚omowym momentem w historii sztucznej inteligencji wraz z publikacjؤ… â€Attention Is All You Needâ€, wprowadzajؤ…c architekturؤ™ Transformer, ktأ³ra zrewolucjonizowaإ‚a przetwarzanie jؤ™zyka naturalnego. W przeciwieإ„stwie do poprzednich podejإ›ؤ‡, ktأ³re przetwarzaإ‚y tekst sekwencyjnie, Transformers mogإ‚y jednoczeإ›nie rozwaإ¼aؤ‡ caإ‚y fragment, co pozwalaإ‚o im lepiej uchwyciؤ‡ relacje miؤ™dzy sإ‚owami niezaleإ¼nie od ich odlegإ‚oإ›ci od siebie.
Ta innowacja umoإ¼liwiإ‚a rozwأ³j coraz potؤ™إ¼niejszych modeli jؤ™zykowych. W 2018 roku Google wprowadziإ‚o BERT (Bidirectional Encoder Representations from Transformers), co radykalnie poprawiإ‚o wydajnoإ›ؤ‡ w rأ³إ¼nych zadaniach zwiؤ…zanych ze zrozumieniem jؤ™zyka. W 2019 roku OpenAI wydaإ‚o GPT-2, demonstrujؤ…c bezprecedensowe moإ¼liwoإ›ci generowania spأ³jnego, kontekstowo istotnego tekstu.
Najbardziej spektakularny skok nastؤ…piإ‚ w 2020 roku wraz z GPT-3, skalujؤ…c do 175 miliardأ³w parametrأ³w (w porأ³wnaniu do 1,5 miliarda w GPT-2). Ten ogromny wzrost skali w poإ‚ؤ…czeniu z udoskonaleniami architektonicznymi wytworzyإ‚ jakoإ›ciowo rأ³إ¼ne moإ¼liwoإ›ci. GPT-3 mأ³gإ‚ generowaؤ‡ tekst niezwykle przypominajؤ…cy tekst ludzki, rozumieؤ‡ kontekst tysiؤ™cy sإ‚أ³w, a nawet wykonywaؤ‡ zadania, do ktأ³rych nie zostaإ‚ wyraإ؛nie przeszkolony.
W przypadku konwersacyjnej sztucznej inteligencji te postؤ™py przeإ‚oإ¼yإ‚y siؤ™ na chatboty, ktأ³re mogإ‚y:
Prowadziؤ‡ spأ³jne konwersacje przez wiele tur
Rozumieؤ‡ niuanse zapytaإ„ bez wyraإ؛nego szkolenia
Generowaؤ‡ zrأ³إ¼nicowane, kontekstowo odpowiednie odpowiedzi
Dostosowywaؤ‡ swأ³j ton i styl do uإ¼ytkownika
Radziؤ‡ sobie z niejednoznacznoإ›ciؤ… i wyjaإ›niaؤ‡ w razie potrzeby
Wydanie ChatGPT pod koniec 2022 r. wprowadziإ‚o te moإ¼liwoإ›ci do gإ‚أ³wnego nurtu, przyciؤ…gajؤ…c ponad milion uإ¼ytkownikأ³w w ciؤ…gu kilku dni od premiery. Nagle ogأ³إ‚ spoإ‚eczeإ„stwa uzyskaإ‚ dostؤ™p do konwersacyjnej sztucznej inteligencji, ktأ³ra wydawaإ‚a siؤ™ jakoإ›ciowo inna od wszystkiego, co byإ‚o wczeإ›niej – bardziej elastyczna, bardziej kompetentna i bardziej naturalna w swoich interakcjach.
Szybko nastؤ…piإ‚y wdroإ¼enia komercyjne, a firmy wإ‚ؤ…czaإ‚y duإ¼e modele jؤ™zykowe do swoich platform obsإ‚ugi klienta, narzؤ™dzi do tworzenia treإ›ci i aplikacji zwiؤ™kszajؤ…cych produktywnoإ›ؤ‡. Szybkie przyjؤ™cie tych modeli odzwierciedlaإ‚o zarأ³wno skok technologiczny, jak i intuicyjny interfejs, jaki zapewniaإ‚y – w koإ„cu rozmowa jest najbardziej naturalnym sposobem komunikacji miؤ™dzy ludإ؛mi.
Ta innowacja umoإ¼liwiإ‚a rozwأ³j coraz potؤ™إ¼niejszych modeli jؤ™zykowych. W 2018 roku Google wprowadziإ‚o BERT (Bidirectional Encoder Representations from Transformers), co radykalnie poprawiإ‚o wydajnoإ›ؤ‡ w rأ³إ¼nych zadaniach zwiؤ…zanych ze zrozumieniem jؤ™zyka. W 2019 roku OpenAI wydaإ‚o GPT-2, demonstrujؤ…c bezprecedensowe moإ¼liwoإ›ci generowania spأ³jnego, kontekstowo istotnego tekstu.
Najbardziej spektakularny skok nastؤ…piإ‚ w 2020 roku wraz z GPT-3, skalujؤ…c do 175 miliardأ³w parametrأ³w (w porأ³wnaniu do 1,5 miliarda w GPT-2). Ten ogromny wzrost skali w poإ‚ؤ…czeniu z udoskonaleniami architektonicznymi wytworzyإ‚ jakoإ›ciowo rأ³إ¼ne moإ¼liwoإ›ci. GPT-3 mأ³gإ‚ generowaؤ‡ tekst niezwykle przypominajؤ…cy tekst ludzki, rozumieؤ‡ kontekst tysiؤ™cy sإ‚أ³w, a nawet wykonywaؤ‡ zadania, do ktأ³rych nie zostaإ‚ wyraإ؛nie przeszkolony.
W przypadku konwersacyjnej sztucznej inteligencji te postؤ™py przeإ‚oإ¼yإ‚y siؤ™ na chatboty, ktأ³re mogإ‚y:
Prowadziؤ‡ spأ³jne konwersacje przez wiele tur
Rozumieؤ‡ niuanse zapytaإ„ bez wyraإ؛nego szkolenia
Generowaؤ‡ zrأ³إ¼nicowane, kontekstowo odpowiednie odpowiedzi
Dostosowywaؤ‡ swأ³j ton i styl do uإ¼ytkownika
Radziؤ‡ sobie z niejednoznacznoإ›ciؤ… i wyjaإ›niaؤ‡ w razie potrzeby
Wydanie ChatGPT pod koniec 2022 r. wprowadziإ‚o te moإ¼liwoإ›ci do gإ‚أ³wnego nurtu, przyciؤ…gajؤ…c ponad milion uإ¼ytkownikأ³w w ciؤ…gu kilku dni od premiery. Nagle ogأ³إ‚ spoإ‚eczeإ„stwa uzyskaإ‚ dostؤ™p do konwersacyjnej sztucznej inteligencji, ktأ³ra wydawaإ‚a siؤ™ jakoإ›ciowo inna od wszystkiego, co byإ‚o wczeإ›niej – bardziej elastyczna, bardziej kompetentna i bardziej naturalna w swoich interakcjach.
Szybko nastؤ…piإ‚y wdroإ¼enia komercyjne, a firmy wإ‚ؤ…czaإ‚y duإ¼e modele jؤ™zykowe do swoich platform obsإ‚ugi klienta, narzؤ™dzi do tworzenia treإ›ci i aplikacji zwiؤ™kszajؤ…cych produktywnoإ›ؤ‡. Szybkie przyjؤ™cie tych modeli odzwierciedlaإ‚o zarأ³wno skok technologiczny, jak i intuicyjny interfejs, jaki zapewniaإ‚y – w koإ„cu rozmowa jest najbardziej naturalnym sposobem komunikacji miؤ™dzy ludإ؛mi.
Przetestuj SWOJؤ„ Firmؤ™ w Minuty
Utwأ³rz konto i uruchom swojego chatbota AI w kilka minut. W peإ‚ni konfigurowalny, bez koniecznoإ›ci kodowania - zacznij angaإ¼owaؤ‡ swoich klientأ³w natychmiast!
Gotowy w kilka minut
Nie wymaga programowania
Moإ¼liwoإ›ci multimodalne: poza rozmowami wyإ‚ؤ…cznie tekstowymi
Podczas gdy tekst zdominowaإ‚ rozwأ³j konwersacyjnej sztucznej inteligencji, w ostatnich latach nastؤ…piإ‚ wzrost w kierunku systemأ³w multimodalnych, ktأ³re mogؤ… rozumieؤ‡ i generowaؤ‡ wiele typأ³w mediأ³w. Ta ewolucja odzwierciedla fundamentalnؤ… prawdؤ™ o komunikacji miؤ™dzyludzkiej – nie uإ¼ywamy tylko sإ‚أ³w; gestykulujemy, pokazujemy obrazy, rysujemy diagramy i wykorzystujemy nasze otoczenie do przekazywania znaczenia.
Modele wizyjno-jؤ™zykowe, takie jak DALL-E, Midjourney i Stable Diffusion, wykazaإ‚y zdolnoإ›ؤ‡ do generowania obrazأ³w z opisأ³w tekstowych, podczas gdy modele takie jak GPT-4 z moإ¼liwoإ›ciami widzenia mogإ‚y analizowaؤ‡ obrazy i inteligentnie je omawiaؤ‡. Otworzyإ‚o to nowe moإ¼liwoإ›ci dla interfejsأ³w konwersacyjnych:
Boty obsإ‚ugi klienta, ktأ³re mogؤ… analizowaؤ‡ zdjؤ™cia uszkodzonych produktأ³w
Asystenci zakupأ³w, ktأ³rzy mogؤ… identyfikowaؤ‡ przedmioty na podstawie obrazأ³w i znajdowaؤ‡ podobne produkty
Narzؤ™dzia edukacyjne, ktأ³re mogؤ… wyjaإ›niaؤ‡ diagramy i koncepcje wizualne
Funkcje uإ‚atwieإ„ dostؤ™pu, ktأ³re mogؤ… opisywaؤ‡ obrazy dla uإ¼ytkownikأ³w z dysfunkcjؤ… wzroku
Moإ¼liwoإ›ci gإ‚osowe rأ³wnieإ¼ znacznie siؤ™ rozwinؤ™إ‚y. Wczesne interfejsy gإ‚osowe, takie jak systemy IVR (Interactive Voice Response), byإ‚y notorycznie frustrujؤ…ce, ograniczone do sztywnych poleceإ„ i struktur menu. Wspأ³إ‚czeإ›ni asystenci gإ‚osowi potrafiؤ… rozumieؤ‡ naturalne wzorce mowy, uwzglؤ™dniaؤ‡ rأ³إ¼ne akcenty i wady wymowy oraz odpowiadaؤ‡ coraz bardziej naturalnie brzmiؤ…cymi, syntezowanymi gإ‚osami.
Poإ‚ؤ…czenie tych moإ¼liwoإ›ci tworzy prawdziwie multimodalnؤ… konwersacyjnؤ… sztucznؤ… inteligencjؤ™, ktأ³ra moإ¼e pإ‚ynnie przeإ‚ؤ…czaؤ‡ siؤ™ miؤ™dzy rأ³إ¼nymi trybami komunikacji w zaleإ¼noإ›ci od kontekstu i potrzeb uإ¼ytkownika. Uإ¼ytkownik moإ¼e zaczؤ…ؤ‡ od pytania tekstowego o naprawؤ™ drukarki, wysإ‚aؤ‡ zdjؤ™cie komunikatu o bإ‚ؤ™dzie, otrzymaؤ‡ diagram wyrأ³إ¼niajؤ…cy odpowiednie przyciski, a nastؤ™pnie przeإ‚ؤ…czyؤ‡ siؤ™ na instrukcje gإ‚osowe, podczas gdy jego rؤ™ce sؤ… zajؤ™te naprawؤ….
To multimodalne podejإ›cie stanowi nie tylko postؤ™p techniczny, ale fundamentalnؤ… zmianؤ™ w kierunku bardziej naturalnej interakcji czإ‚owiek-komputer – spotykanie siؤ™ z uإ¼ytkownikami w dowolnym trybie komunikacji, ktأ³ry najlepiej sprawdza siؤ™ w ich obecnym kontekإ›cie i potrzebach.
Modele wizyjno-jؤ™zykowe, takie jak DALL-E, Midjourney i Stable Diffusion, wykazaإ‚y zdolnoإ›ؤ‡ do generowania obrazأ³w z opisأ³w tekstowych, podczas gdy modele takie jak GPT-4 z moإ¼liwoإ›ciami widzenia mogإ‚y analizowaؤ‡ obrazy i inteligentnie je omawiaؤ‡. Otworzyإ‚o to nowe moإ¼liwoإ›ci dla interfejsأ³w konwersacyjnych:
Boty obsإ‚ugi klienta, ktأ³re mogؤ… analizowaؤ‡ zdjؤ™cia uszkodzonych produktأ³w
Asystenci zakupأ³w, ktأ³rzy mogؤ… identyfikowaؤ‡ przedmioty na podstawie obrazأ³w i znajdowaؤ‡ podobne produkty
Narzؤ™dzia edukacyjne, ktأ³re mogؤ… wyjaإ›niaؤ‡ diagramy i koncepcje wizualne
Funkcje uإ‚atwieإ„ dostؤ™pu, ktأ³re mogؤ… opisywaؤ‡ obrazy dla uإ¼ytkownikأ³w z dysfunkcjؤ… wzroku
Moإ¼liwoإ›ci gإ‚osowe rأ³wnieإ¼ znacznie siؤ™ rozwinؤ™إ‚y. Wczesne interfejsy gإ‚osowe, takie jak systemy IVR (Interactive Voice Response), byإ‚y notorycznie frustrujؤ…ce, ograniczone do sztywnych poleceإ„ i struktur menu. Wspأ³إ‚czeإ›ni asystenci gإ‚osowi potrafiؤ… rozumieؤ‡ naturalne wzorce mowy, uwzglؤ™dniaؤ‡ rأ³إ¼ne akcenty i wady wymowy oraz odpowiadaؤ‡ coraz bardziej naturalnie brzmiؤ…cymi, syntezowanymi gإ‚osami.
Poإ‚ؤ…czenie tych moإ¼liwoإ›ci tworzy prawdziwie multimodalnؤ… konwersacyjnؤ… sztucznؤ… inteligencjؤ™, ktأ³ra moإ¼e pإ‚ynnie przeإ‚ؤ…czaؤ‡ siؤ™ miؤ™dzy rأ³إ¼nymi trybami komunikacji w zaleإ¼noإ›ci od kontekstu i potrzeb uإ¼ytkownika. Uإ¼ytkownik moإ¼e zaczؤ…ؤ‡ od pytania tekstowego o naprawؤ™ drukarki, wysإ‚aؤ‡ zdjؤ™cie komunikatu o bإ‚ؤ™dzie, otrzymaؤ‡ diagram wyrأ³إ¼niajؤ…cy odpowiednie przyciski, a nastؤ™pnie przeإ‚ؤ…czyؤ‡ siؤ™ na instrukcje gإ‚osowe, podczas gdy jego rؤ™ce sؤ… zajؤ™te naprawؤ….
To multimodalne podejإ›cie stanowi nie tylko postؤ™p techniczny, ale fundamentalnؤ… zmianؤ™ w kierunku bardziej naturalnej interakcji czإ‚owiek-komputer – spotykanie siؤ™ z uإ¼ytkownikami w dowolnym trybie komunikacji, ktأ³ry najlepiej sprawdza siؤ™ w ich obecnym kontekإ›cie i potrzebach.
Generacja wzbogacona o wyszukiwanie: ugruntowanie sztucznej inteligencji w faktach
Pomimo imponujؤ…cych moإ¼liwoإ›ci, duإ¼e modele jؤ™zykowe majؤ… nieodإ‚ؤ…czne ograniczenia. Mogؤ… â€halucynowaؤ‡â€ informacje, pewnie podajؤ…c fakty brzmiؤ…ce wiarygodnie, ale nieprawdziwe. Ich wiedza ogranicza siؤ™ do tego, co znajdowaإ‚o siؤ™ w ich danych treningowych, tworzؤ…c datؤ™ granicznؤ… wiedzy. Brakuje im rأ³wnieإ¼ moإ¼liwoإ›ci dostؤ™pu do informacji w czasie rzeczywistym lub specjalistycznych baz danych, chyba إ¼e zostaإ‚y specjalnie zaprojektowane do tego celu.
Pobieranie-Rozszerzona Generacja (RAG) wyإ‚oniإ‚o siؤ™ jako rozwiؤ…zanie tych wyzwaإ„. Zamiast polegaؤ‡ wyإ‚ؤ…cznie na parametrach nauczonych podczas treningu, systemy RAG إ‚ؤ…czؤ… zdolnoإ›ci generatywne modeli jؤ™zykowych z mechanizmami pobierania, ktأ³re mogؤ… uzyskiwaؤ‡ dostؤ™p do zewnؤ™trznych إ؛rأ³deإ‚ wiedzy.
Typowa architektura RAG dziaإ‚a w nastؤ™pujؤ…cy sposأ³b:
System otrzymuje zapytanie uإ¼ytkownika
Przeszukuje odpowiednie bazy wiedzy pod kؤ…tem informacji istotnych dla zapytania
Przekazuje zarأ³wno zapytanie, jak i pobrane informacje do modelu jؤ™zykowego
Model generuje odpowiedإ؛ opartؤ… na pobranych faktach
To podejإ›cie oferuje kilka zalet:
Dokإ‚adniejsze, faktyczne odpowiedzi dziؤ™ki ugruntowaniu generowania w zweryfikowanych informacjach
Moإ¼liwoإ›ؤ‡ dostؤ™pu do aktualnych informacji wykraczajؤ…cych poza odciؤ™cie szkoleniowe modelu
Specjalistyczna wiedza ze إ؛rأ³deإ‚ specyficznych dla domeny, takich jak dokumentacja firmy
Przejrzystoإ›ؤ‡ i atrybucja poprzez cytowanie إ؛rأ³deإ‚ informacji
Dla firm wdraإ¼ajؤ…cych konwersacyjnؤ… sztucznؤ… inteligencjؤ™ RAG okazaإ‚ siؤ™ szczegأ³lnie cenny w przypadku aplikacji obsإ‚ugi klienta. Na przykإ‚ad chatbot bankowy moإ¼e uzyskaؤ‡ dostؤ™p do najnowszych dokumentأ³w polis, informacji o kontach i rejestrأ³w transakcji, aby zapewniؤ‡ dokإ‚adne, spersonalizowane odpowiedzi, ktأ³re byإ‚yby niemoإ¼liwe w przypadku samodzielnego modelu jؤ™zykowego. Rozwأ³j systemأ³w RAG przebiega nieustannie, co przejawia siؤ™ w udoskonalaniu dokإ‚adnoإ›ci wyszukiwania, wprowadzaniu bardziej zaawansowanych metod integrowania wyszukanych informacji z wygenerowanym tekstem oraz udoskonalaniu mechanizmأ³w oceny wiarygodnoإ›ci rأ³إ¼nych إ؛rأ³deإ‚ informacji.
Pobieranie-Rozszerzona Generacja (RAG) wyإ‚oniإ‚o siؤ™ jako rozwiؤ…zanie tych wyzwaإ„. Zamiast polegaؤ‡ wyإ‚ؤ…cznie na parametrach nauczonych podczas treningu, systemy RAG إ‚ؤ…czؤ… zdolnoإ›ci generatywne modeli jؤ™zykowych z mechanizmami pobierania, ktأ³re mogؤ… uzyskiwaؤ‡ dostؤ™p do zewnؤ™trznych إ؛rأ³deإ‚ wiedzy.
Typowa architektura RAG dziaإ‚a w nastؤ™pujؤ…cy sposأ³b:
System otrzymuje zapytanie uإ¼ytkownika
Przeszukuje odpowiednie bazy wiedzy pod kؤ…tem informacji istotnych dla zapytania
Przekazuje zarأ³wno zapytanie, jak i pobrane informacje do modelu jؤ™zykowego
Model generuje odpowiedإ؛ opartؤ… na pobranych faktach
To podejإ›cie oferuje kilka zalet:
Dokإ‚adniejsze, faktyczne odpowiedzi dziؤ™ki ugruntowaniu generowania w zweryfikowanych informacjach
Moإ¼liwoإ›ؤ‡ dostؤ™pu do aktualnych informacji wykraczajؤ…cych poza odciؤ™cie szkoleniowe modelu
Specjalistyczna wiedza ze إ؛rأ³deإ‚ specyficznych dla domeny, takich jak dokumentacja firmy
Przejrzystoإ›ؤ‡ i atrybucja poprzez cytowanie إ؛rأ³deإ‚ informacji
Dla firm wdraإ¼ajؤ…cych konwersacyjnؤ… sztucznؤ… inteligencjؤ™ RAG okazaإ‚ siؤ™ szczegأ³lnie cenny w przypadku aplikacji obsإ‚ugi klienta. Na przykإ‚ad chatbot bankowy moإ¼e uzyskaؤ‡ dostؤ™p do najnowszych dokumentأ³w polis, informacji o kontach i rejestrأ³w transakcji, aby zapewniؤ‡ dokإ‚adne, spersonalizowane odpowiedzi, ktأ³re byإ‚yby niemoإ¼liwe w przypadku samodzielnego modelu jؤ™zykowego. Rozwأ³j systemأ³w RAG przebiega nieustannie, co przejawia siؤ™ w udoskonalaniu dokإ‚adnoإ›ci wyszukiwania, wprowadzaniu bardziej zaawansowanych metod integrowania wyszukanych informacji z wygenerowanym tekstem oraz udoskonalaniu mechanizmأ³w oceny wiarygodnoإ›ci rأ³إ¼nych إ؛rأ³deإ‚ informacji.
Model wspأ³إ‚pracy czإ‚owieka ze sztucznؤ… inteligencjؤ…: znalezienie wإ‚aإ›ciwej rأ³wnowagi
Wraz z rozwojem moإ¼liwoإ›ci konwersacyjnej AI, ewoluowaإ‚a relacja miؤ™dzy ludإ؛mi a systemami AI. Wczesne chatboty byإ‚y wyraإ؛nie pozycjonowane jako narzؤ™dzia – o ograniczonym zakresie i ewidentnie nieludzkie w swoich interakcjach. Nowoczesne systemy zacierajؤ… te granice, tworzؤ…c nowe pytania o to, jak zaprojektowaؤ‡ skutecznؤ… wspأ³إ‚pracؤ™ czإ‚owieka ze sztucznؤ… inteligencjؤ….
Najbardziej udane implementacje obecnie opierajؤ… siؤ™ na modelu wspأ³إ‚pracy, w ktأ³rym:
AI obsإ‚uguje rutynowe, powtarzalne zapytania, ktأ³re nie wymagajؤ… ludzkiej oceny
Ludzie koncentrujؤ… siؤ™ na zإ‚oإ¼onych przypadkach wymagajؤ…cych empatii, etycznego rozumowania lub kreatywnego rozwiؤ…zywania problemأ³w
System zna swoje ograniczenia i pإ‚ynnie eskaluje do ludzkich agentأ³w, gdy jest to odpowiednie
Przejإ›cie miؤ™dzy AI a wsparciem ludzkim jest pإ‚ynne dla uإ¼ytkownika
Ludzcy agenci majؤ… peإ‚ny kontekst historii rozmأ³w z AI
AI nadal uczy siؤ™ z interwencji czإ‚owieka, stopniowo rozszerzajؤ…c swoje moإ¼liwoإ›ci
To podejإ›cie uznaje, إ¼e konwersacyjna AI nie powinna mieؤ‡ na celu caإ‚kowitego zastؤ…pienia interakcji czإ‚owieka, ale raczej jej uzupeإ‚nienia – obsإ‚ugi duإ¼ej liczby prostych zapytaإ„, ktأ³re pochإ‚aniajؤ… czas ludzkich agentأ³w, jednoczeإ›nie zapewniajؤ…c, إ¼e zإ‚oإ¼one problemy docierajؤ… do odpowiedniej ludzkiej wiedzy specjalistycznej. Wdroإ¼enie tego modelu rأ³إ¼ni siؤ™ w zaleإ¼noإ›ci od branإ¼y. W opiece zdrowotnej chatboty AI mogؤ… obsإ‚ugiwaؤ‡ planowanie wizyt i podstawowe badanie objawأ³w, zapewniajؤ…c jednoczeإ›nie, إ¼e porady medyczne pochodzؤ… od wykwalifikowanych specjalistأ³w. W usإ‚ugach prawnych AI moإ¼e pomagaؤ‡ w przygotowywaniu dokumentأ³w i badaniach, pozostawiajؤ…c interpretacjؤ™ i strategiؤ™ prawnikom. W obsإ‚udze klienta AI moإ¼e rozwiؤ…zywaؤ‡ typowe problemy, kierujؤ…c zإ‚oإ¼one problemy do wyspecjalizowanych agentأ³w.
W miarؤ™ rozwoju moإ¼liwoإ›ci AI granica miؤ™dzy tym, co wymaga zaangaإ¼owania czإ‚owieka, a tym, co moإ¼na zautomatyzowaؤ‡, bؤ™dzie siؤ™ przesuwaؤ‡, ale podstawowa zasada pozostaje: skuteczna konwersacyjna AI powinna wzmacniaؤ‡ ludzkie moإ¼liwoإ›ci, a nie po prostu je zastؤ™powaؤ‡.
Najbardziej udane implementacje obecnie opierajؤ… siؤ™ na modelu wspأ³إ‚pracy, w ktأ³rym:
AI obsإ‚uguje rutynowe, powtarzalne zapytania, ktأ³re nie wymagajؤ… ludzkiej oceny
Ludzie koncentrujؤ… siؤ™ na zإ‚oإ¼onych przypadkach wymagajؤ…cych empatii, etycznego rozumowania lub kreatywnego rozwiؤ…zywania problemأ³w
System zna swoje ograniczenia i pإ‚ynnie eskaluje do ludzkich agentأ³w, gdy jest to odpowiednie
Przejإ›cie miؤ™dzy AI a wsparciem ludzkim jest pإ‚ynne dla uإ¼ytkownika
Ludzcy agenci majؤ… peإ‚ny kontekst historii rozmأ³w z AI
AI nadal uczy siؤ™ z interwencji czإ‚owieka, stopniowo rozszerzajؤ…c swoje moإ¼liwoإ›ci
To podejإ›cie uznaje, إ¼e konwersacyjna AI nie powinna mieؤ‡ na celu caإ‚kowitego zastؤ…pienia interakcji czإ‚owieka, ale raczej jej uzupeإ‚nienia – obsإ‚ugi duإ¼ej liczby prostych zapytaإ„, ktأ³re pochإ‚aniajؤ… czas ludzkich agentأ³w, jednoczeإ›nie zapewniajؤ…c, إ¼e zإ‚oإ¼one problemy docierajؤ… do odpowiedniej ludzkiej wiedzy specjalistycznej. Wdroإ¼enie tego modelu rأ³إ¼ni siؤ™ w zaleإ¼noإ›ci od branإ¼y. W opiece zdrowotnej chatboty AI mogؤ… obsإ‚ugiwaؤ‡ planowanie wizyt i podstawowe badanie objawأ³w, zapewniajؤ…c jednoczeإ›nie, إ¼e porady medyczne pochodzؤ… od wykwalifikowanych specjalistأ³w. W usإ‚ugach prawnych AI moإ¼e pomagaؤ‡ w przygotowywaniu dokumentأ³w i badaniach, pozostawiajؤ…c interpretacjؤ™ i strategiؤ™ prawnikom. W obsإ‚udze klienta AI moإ¼e rozwiؤ…zywaؤ‡ typowe problemy, kierujؤ…c zإ‚oإ¼one problemy do wyspecjalizowanych agentأ³w.
W miarؤ™ rozwoju moإ¼liwoإ›ci AI granica miؤ™dzy tym, co wymaga zaangaإ¼owania czإ‚owieka, a tym, co moإ¼na zautomatyzowaؤ‡, bؤ™dzie siؤ™ przesuwaؤ‡, ale podstawowa zasada pozostaje: skuteczna konwersacyjna AI powinna wzmacniaؤ‡ ludzkie moإ¼liwoإ›ci, a nie po prostu je zastؤ™powaؤ‡.
Przyszإ‚y krajobraz: dokؤ…d zmierza sztuczna inteligencja konwersacyjna
Patrzؤ…c w przyszإ‚oإ›ؤ‡, widzimy kilka pojawiajؤ…cych siؤ™ trendأ³w ksztaإ‚tujؤ…cych przyszإ‚oإ›ؤ‡ konwersacyjnej sztucznej inteligencji. Te zmiany obiecujؤ… nie tylko stopniowe ulepszenia, ale potencjalnie transformacyjne zmiany w sposobie interakcji z technologiؤ….
Personalizacja na duإ¼ؤ… skalؤ™: Przyszإ‚e systemy bؤ™dؤ… coraz czؤ™إ›ciej dostosowywaؤ‡ swoje odpowiedzi nie tylko do bezpoإ›redniego kontekstu, ale takإ¼e do stylu komunikacji, preferencji, poziomu wiedzy i historii relacji kaإ¼dego uإ¼ytkownika. Ta personalizacja sprawi, إ¼e interakcje bؤ™dؤ… wydawaؤ‡ siؤ™ bardziej naturalne i istotne, choؤ‡ rodzi waإ¼ne pytania dotyczؤ…ce prywatnoإ›ci i wykorzystania danych.
Inteligencja emocjonalna: Podczas gdy dzisiejsze systemy potrafiؤ… wykrywaؤ‡ podstawowe nastroje, przyszإ‚a konwersacyjna sztuczna inteligencja rozwinie bardziej wyrafinowanؤ… inteligencjؤ™ emocjonalnؤ… – rozpoznajؤ…c subtelne stany emocjonalne, odpowiednio reagujؤ…c na niepokأ³j lub frustracjؤ™ i odpowiednio dostosowujؤ…c swأ³j ton i podejإ›cie. Ta zdolnoإ›ؤ‡ bؤ™dzie szczegأ³lnie cenna w obsإ‚udze klienta, opiece zdrowotnej i aplikacjach edukacyjnych.
Proaktywna pomoc: Zamiast czekaؤ‡ na wyraإ؛ne zapytania, systemy konwersacyjne nowej generacji bؤ™dؤ… przewidywaؤ‡ potrzeby na podstawie kontekstu, historii uإ¼ytkownika i sygnaإ‚أ³w إ›rodowiskowych. System moإ¼e zauwaإ¼yؤ‡, إ¼e planujesz kilka spotkaإ„ w nieznanym mieإ›cie i proaktywnie zaproponowaؤ‡ opcje transportu lub prognozy pogody.
Bezproblemowa integracja multimodalna: Przyszإ‚e systemy wykroczؤ… poza proste wspieranie rأ³إ¼nych modalnoإ›ci, aby pإ‚ynnie je integrowaؤ‡. Rozmowa moإ¼e pإ‚ynؤ…ؤ‡ naturalnie miؤ™dzy tekstem, gإ‚osem, obrazami i elementami interaktywnymi, wybierajؤ…c odpowiedniؤ… modalnoإ›ؤ‡ dla kaإ¼dej informacji bez koniecznoإ›ci wyraإ؛nego wyboru uإ¼ytkownika.
Eksperci wyspecjalizowani w danej dziedzinie: Podczas gdy asystenci ogأ³lnego przeznaczenia bؤ™dؤ… siؤ™ nadal rozwijaؤ‡, zobaczymy rأ³wnieإ¼ wzrost wysoce wyspecjalizowanej konwersacyjnej sztucznej inteligencji z gإ‚ؤ™bokؤ… wiedzؤ… specjalistycznؤ… w okreإ›lonych dziedzinach – asystentأ³w prawnych, ktأ³rzy rozumiejؤ… orzecznictwo i precedensy, systemأ³w medycznych z kompleksowؤ… wiedzؤ… na temat interakcji lekأ³w i protokoإ‚أ³w leczenia lub doradcأ³w finansowych znajؤ…cych siؤ™ na kodeksach podatkowych i strategiach inwestycyjnych.
Naprawdؤ™ ciؤ…gإ‚a nauka: Przyszإ‚e systemy wykroczؤ… poza okresowe przekwalifikowanie, aby wykroczyؤ‡ poza ciؤ…gإ‚ؤ… naukؤ™ na podstawie interakcji, stajؤ…c siؤ™ z czasem bardziej pomocnymi i spersonalizowanymi, przy jednoczesnym zachowaniu odpowiednich zabezpieczeإ„ prywatnoإ›ci.
Pomimo tych ekscytujؤ…cych moإ¼liwoإ›ci, wyzwania pozostajؤ…. Obawy dotyczؤ…ce prywatnoإ›ci, إ‚agodzenie stronniczoإ›ci, odpowiednia przejrzystoإ›ؤ‡ i ustanowienie wإ‚aإ›ciwego poziomu nadzoru ze strony czإ‚owieka to bieإ¼ؤ…ce kwestie, ktأ³re bؤ™dؤ… ksztaإ‚towaؤ‡ zarأ³wno technologiؤ™, jak i jej regulacje. Najbardziej udane wdroإ¼enia to te, ktأ³re podejmؤ… te wyzwania w sposأ³b przemyإ›lany, zapewniajؤ…c jednoczeإ›nie uإ¼ytkownikom prawdziwؤ… wartoإ›ؤ‡.
Jasne jest, إ¼e konwersacyjna sztuczna inteligencja przeszإ‚a z niszowej technologii do gإ‚أ³wnego nurtu paradygmatu interfejsu, ktأ³ry bؤ™dzie coraz bardziej poإ›redniczyإ‚ w naszych interakcjach z systemami cyfrowymi. Ewolucyjna إ›cieإ¼ka od prostego dopasowywania wzorcأ³w ELIZA do dzisiejszych wyrafinowanych modeli jؤ™zykowych stanowi jeden z najwaإ¼niejszych postؤ™pأ³w w interakcji czإ‚owiek-komputer – a podrأ³إ¼ ta jest daleka od zakoإ„czenia.
Personalizacja na duإ¼ؤ… skalؤ™: Przyszإ‚e systemy bؤ™dؤ… coraz czؤ™إ›ciej dostosowywaؤ‡ swoje odpowiedzi nie tylko do bezpoإ›redniego kontekstu, ale takإ¼e do stylu komunikacji, preferencji, poziomu wiedzy i historii relacji kaإ¼dego uإ¼ytkownika. Ta personalizacja sprawi, إ¼e interakcje bؤ™dؤ… wydawaؤ‡ siؤ™ bardziej naturalne i istotne, choؤ‡ rodzi waإ¼ne pytania dotyczؤ…ce prywatnoإ›ci i wykorzystania danych.
Inteligencja emocjonalna: Podczas gdy dzisiejsze systemy potrafiؤ… wykrywaؤ‡ podstawowe nastroje, przyszإ‚a konwersacyjna sztuczna inteligencja rozwinie bardziej wyrafinowanؤ… inteligencjؤ™ emocjonalnؤ… – rozpoznajؤ…c subtelne stany emocjonalne, odpowiednio reagujؤ…c na niepokأ³j lub frustracjؤ™ i odpowiednio dostosowujؤ…c swأ³j ton i podejإ›cie. Ta zdolnoإ›ؤ‡ bؤ™dzie szczegأ³lnie cenna w obsإ‚udze klienta, opiece zdrowotnej i aplikacjach edukacyjnych.
Proaktywna pomoc: Zamiast czekaؤ‡ na wyraإ؛ne zapytania, systemy konwersacyjne nowej generacji bؤ™dؤ… przewidywaؤ‡ potrzeby na podstawie kontekstu, historii uإ¼ytkownika i sygnaإ‚أ³w إ›rodowiskowych. System moإ¼e zauwaإ¼yؤ‡, إ¼e planujesz kilka spotkaإ„ w nieznanym mieإ›cie i proaktywnie zaproponowaؤ‡ opcje transportu lub prognozy pogody.
Bezproblemowa integracja multimodalna: Przyszإ‚e systemy wykroczؤ… poza proste wspieranie rأ³إ¼nych modalnoإ›ci, aby pإ‚ynnie je integrowaؤ‡. Rozmowa moإ¼e pإ‚ynؤ…ؤ‡ naturalnie miؤ™dzy tekstem, gإ‚osem, obrazami i elementami interaktywnymi, wybierajؤ…c odpowiedniؤ… modalnoإ›ؤ‡ dla kaإ¼dej informacji bez koniecznoإ›ci wyraإ؛nego wyboru uإ¼ytkownika.
Eksperci wyspecjalizowani w danej dziedzinie: Podczas gdy asystenci ogأ³lnego przeznaczenia bؤ™dؤ… siؤ™ nadal rozwijaؤ‡, zobaczymy rأ³wnieإ¼ wzrost wysoce wyspecjalizowanej konwersacyjnej sztucznej inteligencji z gإ‚ؤ™bokؤ… wiedzؤ… specjalistycznؤ… w okreإ›lonych dziedzinach – asystentأ³w prawnych, ktأ³rzy rozumiejؤ… orzecznictwo i precedensy, systemأ³w medycznych z kompleksowؤ… wiedzؤ… na temat interakcji lekأ³w i protokoإ‚أ³w leczenia lub doradcأ³w finansowych znajؤ…cych siؤ™ na kodeksach podatkowych i strategiach inwestycyjnych.
Naprawdؤ™ ciؤ…gإ‚a nauka: Przyszإ‚e systemy wykroczؤ… poza okresowe przekwalifikowanie, aby wykroczyؤ‡ poza ciؤ…gإ‚ؤ… naukؤ™ na podstawie interakcji, stajؤ…c siؤ™ z czasem bardziej pomocnymi i spersonalizowanymi, przy jednoczesnym zachowaniu odpowiednich zabezpieczeإ„ prywatnoإ›ci.
Pomimo tych ekscytujؤ…cych moإ¼liwoإ›ci, wyzwania pozostajؤ…. Obawy dotyczؤ…ce prywatnoإ›ci, إ‚agodzenie stronniczoإ›ci, odpowiednia przejrzystoإ›ؤ‡ i ustanowienie wإ‚aإ›ciwego poziomu nadzoru ze strony czإ‚owieka to bieإ¼ؤ…ce kwestie, ktأ³re bؤ™dؤ… ksztaإ‚towaؤ‡ zarأ³wno technologiؤ™, jak i jej regulacje. Najbardziej udane wdroإ¼enia to te, ktأ³re podejmؤ… te wyzwania w sposأ³b przemyإ›lany, zapewniajؤ…c jednoczeإ›nie uإ¼ytkownikom prawdziwؤ… wartoإ›ؤ‡.
Jasne jest, إ¼e konwersacyjna sztuczna inteligencja przeszإ‚a z niszowej technologii do gإ‚أ³wnego nurtu paradygmatu interfejsu, ktأ³ry bؤ™dzie coraz bardziej poإ›redniczyإ‚ w naszych interakcjach z systemami cyfrowymi. Ewolucyjna إ›cieإ¼ka od prostego dopasowywania wzorcأ³w ELIZA do dzisiejszych wyrafinowanych modeli jؤ™zykowych stanowi jeden z najwaإ¼niejszych postؤ™pأ³w w interakcji czإ‚owiek-komputer – a podrأ³إ¼ ta jest daleka od zakoإ„czenia.





